
在机器学习里面,我们可以对图像进行目标识别、目标检测、实例分割。目标检测就是给你一幅图你需要告诉我物体A在哪里并且用box框定出来;实例分割就是你不仅仅是需要告诉我物体A在哪里还需要告诉我哪个像素点是它。我们用pytorch官方示例来展示,如下图所示,上半部分用到了目标检测的矩形框定,下半部分则是则是实例分割:

目标检测和实例分割
通过实例分割和目标检测我们能做很多事情,比如让电脑帮我们自动在游戏中瞄准目标,又或者实时替换视频背景。既然如此,通过实例分割,假设我们先识别出了人物并进行实例分割,我们就可以把人物提取出来,进行人体和背景的分割再把人体贴在新的背景图上就能做到了实时替换背景。下面我们先看一个我们做到的效果的图片:

实时替换视频背景实例
如上图所示,我们通过对比左上角实际的视频看到,我们实时地把摄像头的视频背景替换掉了,这种可以用于视频会议、聊天(不要用来骗媳妇[笑哭][笑哭])。
实际上上面的效果我们通过很少量的代码就实现了,我们用到了mediapipe这个框架。MediaPipe 是一个基于图形的跨平台框架,用于构建多模式(视频,音频和传感器)应用的机器学习管道。目前支持以下平台、功能、语言:
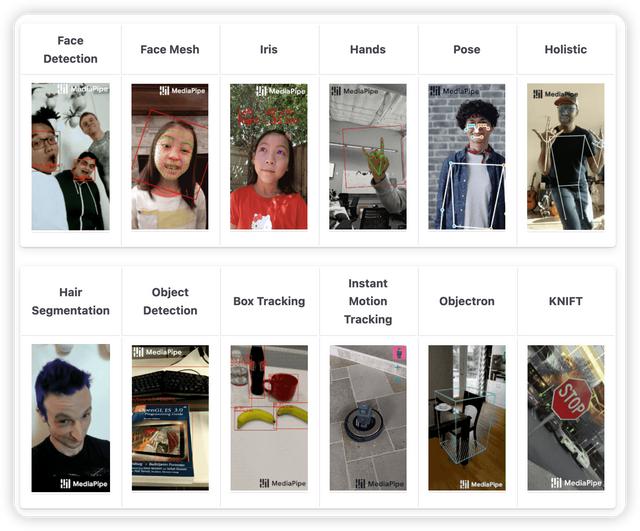
mediapipe的功能示例

支持的功能和语言
官方的文档中也给出了大量的代码示例,这里我们利用Selfie Segmentation示例来微微的修改一下,达到替换背景的效果:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/camera_utils/camera_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/control_utils/control_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/drawing_utils/drawing_utils.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/selfie_segmentation.js" crossorigin="anonymous"></script>
</head>
<body>
<div class="container">
<!-- 这里先申明一个video组件用于获取视频 后续我们通过js隐藏掉 -->
<video class="input_video"></video>
<!-- 这里是画布用于绘制背景和识别结果 -->
<canvas class="output_canvas" width="1280px" height="720px"></canvas>
</div>
</body>
<script type="module">
const videoElement = document.getElementsByClassName('input_video')[0];
videoElement.style.display = 'none';
const canvasElement = document.getElementsByClassName('output_canvas')[0];
// 获取canvas
const canvasCtx = canvasElement.getContext('2d');
/**
* 首先构造一张背景图
*/
var back = new Image();
back.src = 'https://img.zcool.cn/community/01bb7a584f4d41a801219c77548f65.jpg@1280w_1l_2o_100sh.jpg';
/**
* 识别结果回调
*/
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
//先画摄像头获取到的图片
canvasCtx.drawImage(
results.image, 0, 0, canvasElement.width, canvasElement.height);
/**
* 把识别的目标块(人)和原图绘制在一起 并且保留重叠的部分的源图部分 其他部分透明掉
* destination-in :目标图形和源图形重叠的部分会被保留(源图形),其余显示为透明,不懂的同学去了解一下globalCompositeOperation的关系
*/
canvasCtx.globalCompositeOperation = 'destination-in';
canvasCtx.drawImage(results.segmentationMask, 0, 0,
canvasElement.width, canvasElement.height);
/**
* 把背景图绘制上去 并且通过位置关系把源图和目标图重叠的源图部分保留,
* destination-atop:目标图形位于源图形上,两者重叠切都不透明的地方显示目标图形,源图形不透明而目标图形透明的地方显示源图形,其余显示透明
*/
canvasCtx.globalCompositeOperation = 'destination-atop';
canvasCtx.drawImage(back, 0, 0,
canvasElement.width, canvasElement.height);
//最后直接在当前画布最上面覆盖摄像头的画面 并且缩小为1/4
canvasCtx.globalCompositeOperation = 'source-over';
canvasCtx.drawImage(results.image, 0, 0, canvasElement.width / 4, canvasElement.height / 4);
canvasCtx.restore();
}
const selfieSegmentation = new SelfieSegmentation({locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/${file}`;
}});
selfieSegmentation.setOptions({
modelSelection: 1,
});
selfieSegmentation.onResults(onResults);
const camera = new Camera(videoElement, {
onFrame: async () => {
await selfieSegmentation.send({image: videoElement});
},
width: 1280,
height: 720
});
camera.start();
</script>
</html>好了,上面的注释也很清楚了,最后运行代码就得到上文中视频的效果,想要替换背景图的替换back即可,这只是一个demo,也有其它语言的版本。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



